CO TO JEST KUBLESS?
Kubeless jest to projekt open-source pozwalający na budowę środowiska Serverless i wdrażanie funkcji działających jako usługa klasterze Kubernetes. Dzięki temu możliwe jest uzyskanie środowiska uruchomieniowego podobnego do tego jakie udostępnia AWS Lambda, Google Cloud Functions oraz inni dostawcy platform Cloud.
JAK DZIAŁA KUBELESS?
Kubeless do definiowania funkcji wykorzystuje CRD Kubernetes (Custom Resource Definition) które należy zainstalować na klastrze. Wszystkie obiekty potrzebne do prawidłowego działania zawarte są w CRD. Dlatego Kubeless reklamuje się jako prawdziwie Kubernetes Native. Framework dostarcza własne CLI (Command Line Interface) do zarządzania obiektami Kubeless. Za jego pomocą możemy wdrażać i zarządzać wdrażaniem funkcji na środowisko. Możliwe jest także wykorzystanie Kubernetes API i definiowanie obiektów w plikach i ich deployment na klastrze w taki sam sposób w jaki wdrażane są na klastrze inne obiekty Kubernetes. Deployment yaml umożliwia także rozszerzanie i nadpisywanie domyślnych ustawień dla zasobów definiowanych przez operatory CRD Kubeless pozwalając tym samym elastyczne dostrajanie konkretnego deploymentu funkcji pod specyfikę danej usługi. Deployment może także zawierać kod źródłowy funkcji. Przykład prostego deploymentu yaml wygląda następująco:
apiVersion: kubeless.io/v1beta1
kind: Function
metadata:
name: get-python
namespace: default
label:
created-by: kubeless
function: get-python
spec:
runtime: python2.7
timeout: "180"
handler: helloget.foo
deps: ""
checksum: sha256:d251999dcbfdeccec385606fd0aec385b214cfc74ede8b6c9e47af71728f6e9a
function-content-type: text
function: |
def foo(event, context):
return "hello world"
WSPIERANE ŚRODOWISKA (JĘZYKI PROGRAMOWANIA)
Ponieważ do definiowania funkcji dostarczany jest tylko sam kod, framework musi ze swojej strony automatycznie przygotować odpowiednie dla tego kodu środowisko na klastrze K8S, w którym będzie on uruchomiony. Obecnie Kubeless dostarcza środowiska uruchomieniowe (Runtime) dla następujących języków:
- NodeJS
- Python
- Ruby
- Go
- Java
- C#
- Ballerina
Możliwe jest również utworzenie własnego środowiska uruchomieniowego (w postaci CRD). Kubeless dostarcza dokumentację jak skonfigurować i dodać własne środowisko uruchomieniowe.
URUCHAMIANIE FUNKCJI
Do wywołania funkcji utworzonych za pomocą Kubeless należy utworzyć Trigger. Obecnie dostępne są cztery rodzaje tego typu obiektu:
HTTP Trigger
Udostępnia wywołanie funkcji przez HTTP. HTTP Trigger służy do udostępnienia funkcji na zewnątrz klastra. Domyślnie utworzone funkcje nie są dostępne publiczne, inne Pody mogą się jednak z nimi komunikować poprzez skojarzony z funkcją serwis. Do poprawnego działania potrzebny jest skonfigurowany kontroler Ingress na klastrze Kubernetes. HTTP Trigger wspiera zabezpieczenie dostępu poprzez: Basic Authentication, TLS oraz CORS.
CronJob Trigger
Służy do wywoływania funkcji zgodnie z podanym harmonogramem czasowym (cron pattern). Do swojego działania wykorzystuje CronJob domyślnie dostępny w Kubernetes. PubSub Trigger Pozwala na wywołanie funkcji na podstawie pojawiających się danych na wcześniej zdefiniowanej kolejce. Funkcja działa wtedy jako konsument tej kolejki – wywołuje się dla każdej pojawiającej się wiadomości na kolejce. Obecnie wspierane są systemy kolejkowe Kafka i NATS. Są dla nich dostępne odpowiednio Kafka Trigger i NATS Trigger. DataStream Trigger Funkcje wywoływane są w odpowiedzi na pojawiające się rekordy w strumieniu danych. Obecnie wspierany jest tylko AWS Kinesis (Kinesis Trigger). Custom Trigger Wszystkie Triggery oparte są o CRD Kubernetes dlatego możliwe jest napisanie własnego niestandardowego triggera – Kubeless udostępnia dokumentację jak go stworzyć.
SKALOWANIE
Kubeless dostarcza możliwość autoskalowania funkcji, czyli liczby kontenerów, które mają obsługiwać napływające żądania. W tym celu wykorzystany jest mechanizm dostarczany przez Kubernetes – HorizontalPodAutoscaler. Możliwe jest zdefiniowanie skalowania na podstawie następujących metryk:
- cpu - procent wykorzystania procesora
- qps - liczba wpływających żądań na sekundę
METRYKI
Każde środowisko automatycznie zbiera metryki na temat wywoływanych funkcji i udostępnia je w formacie obsługiwanym przez Prometheus. Na ich podstawie dowiemy się między innymi o częstotliwości wywoływania funkcji, liczby błędów lub czasie wykonywania funkcji.
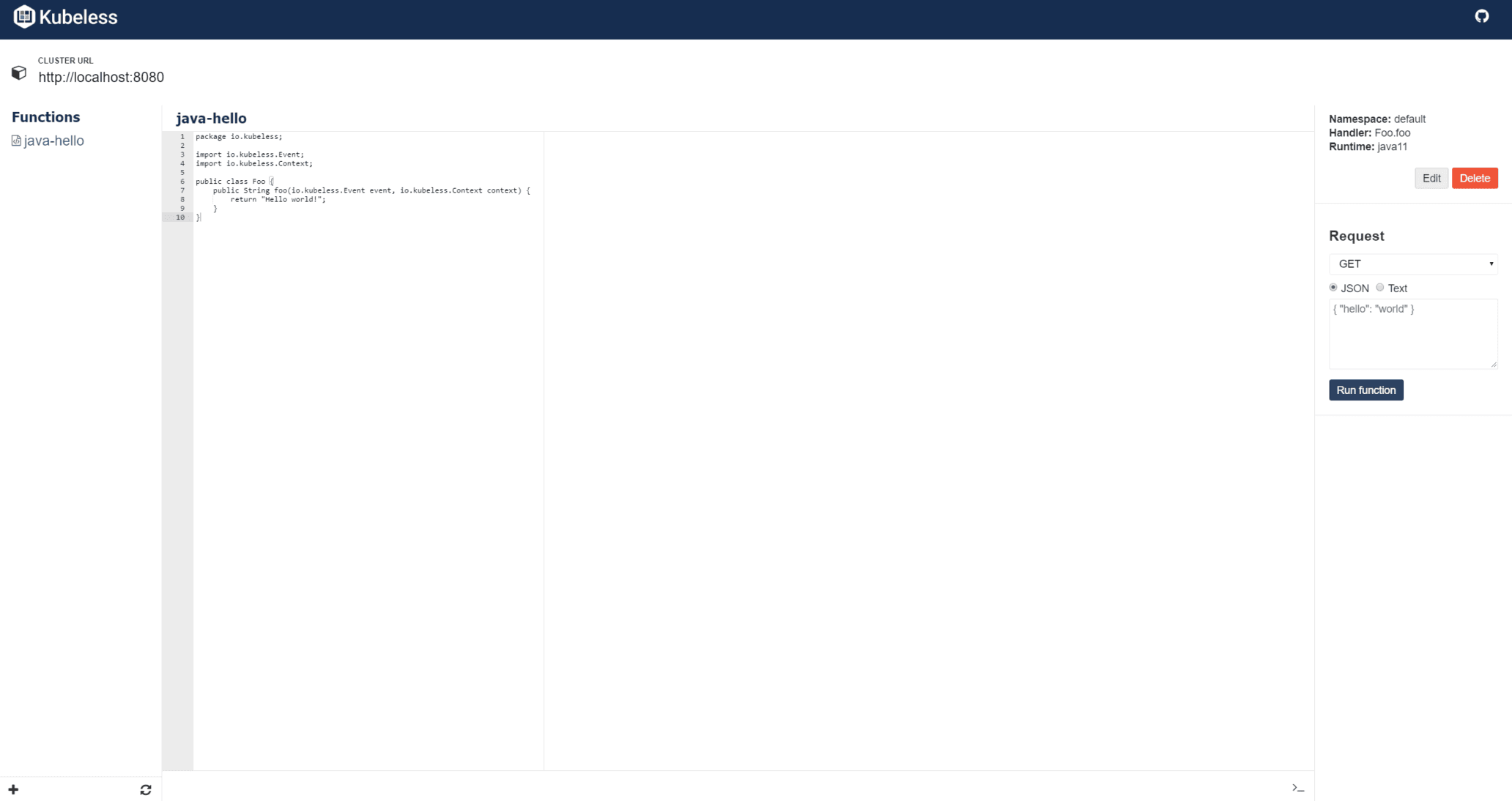
UI
Kubeless dostarcza proste GUI (kubeless-ui). Pozwala tworzyć nowe i modyfikować istniejące funkcje. Umożliwia również wywołanie danej funkcji z poziomu GUI.
PODSUMOWANIE
Kubeless jest to relatywnie prosty we wdrożeniu i użyciu framework umożliwiający stworzenie środowiska Serverless typu Function As a Service. Środowisko działa w oparciu o mechanizmy klastra Kubernetes, a osoba wdrażająca kod nie musi znać specyfiki działania klastra aby uruchomić ją na środowisku z wykorzystaniem CLI. Kubeless (jak również inne środowiska serverless) może sprawdzić się gdy potrzebujemy środowiska do realizacji atomowych funkcjonalności, które powinno się dynamicznie skalować np. w architekturze typu Event Driven. Przykładem może być przetwarzanie dużych wolumenów danych w obszarach Big Data lub w procesach ETL gdy obciążenie systemu może być nierównomiernie rozłożone w czasie przez napływające dane. Serverless może sprawdzić się także w środowiskach realizujących dużą liczbę prostych i wzajemnie niezależnych usług o krótkim czasie wykonania np w obszarze DevOps na klastrze Kubernetes.